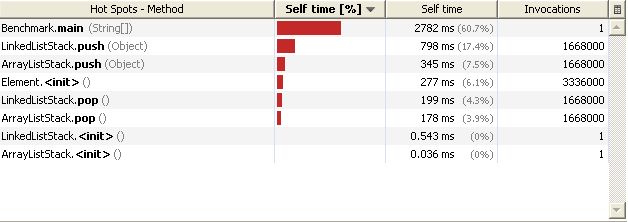
This is a classic exercise to illustrate the use of TreeModel. So we’ll explain here how to use TreeModel to display the filesystem. _TreeModels are an example of MVC in action in Swing, and the way it’s used is pretty much recurrent in the “complicated” Swing components, such as lists, tables, trees…
The first thing we want is a class that will represent a node in the tree model:
public class FileNode extends java.io.File {
public FileNode(String directory) {
super(directory);
}
public FileNode(FileNode parent, String child) {
super(parent, child);
}
@Override
public String toString() {
return getName();
}
}
This class is pretty much only needed for overriding the toString() of the File class so that we don’t have too much work for displaying the nodes (we’ll probably see in a later edition that there is another way…). Now that we have the nodes, here is the table model implementation. You’ll see that it merely adapts the model to call the corresponding java.io.File methods:
import java.util.Arrays;
import javax.swing.event.TreeModelListener;
import javax.swing.tree.TreeModel;
import javax.swing.tree.TreePath;
public class FileSelectorModel implements TreeModel {
private FileNode root;
/**
* the constructor defines the root.
*/
public FileSelectorModel(String directory) {
root = new FileNode(directory);
}
public Object getRoot() {
return root;
}
/**
* returns the <code>parent</code>’s child located at index <code>index</code>.
*/
public Object getChild(Object parent, int index) {
FileNode parentNode = (FileNode) parent;
return new FileNode(parentNode,
parentNode.listFiles()[index].getName());
}
/**
* returns the number of child. If the node is not a directory, or its list of children
* is null, returns 0. Otherwise, just return the number of files under the current file.
*/
public int getChildCount(Object parent) {
FileNode parentNode = (FileNode) parent;
if (parent == null
|| !parentNode.isDirectory()
|| parentNode.listFiles() == null) {
return 0;
}
return parentNode.listFiles().length;
}
/**
* returns true if {{@link #getChildCount(Object)} is 0.
*/
public boolean isLeaf(Object node) {
return (getChildCount(node) == 0);
}
/**
* return the index of the child in the list of files under <code>parent</code>.
*/
public int getIndexOfChild(Object parent, Object child) {
FileNode parentNode = (FileNode) parent;
FileNode childNode = (FileNode) child;
return Arrays.asList(parentNode.list()).indexOf(childNode.getName());
}
// The following methods are not implemented, as we won’t need them for this example.
public void valueForPathChanged(TreePath path, Object newValue) {
}
public void addTreeModelListener(TreeModelListener l) {
}
public void removeTreeModelListener(TreeModelListener l) {
}
}
Nothing really complicated in there.
And now, we just have to put everything together by inserting the Swing components in the frame:
import java.awt.BorderLayout;
import java.io.BufferedReader;
import java.io.FileReader;
import javax.swing.JFrame;
import javax.swing.JLabel;
import javax.swing.JScrollPane;
import javax.swing.JTextArea;
import javax.swing.JTree;
import javax.swing.event.TreeSelectionEvent;
import javax.swing.event.TreeSelectionListener;
public class FilePreviewer extends JFrame {
private JTree tree;
private JTextArea preview;
private JLabel status;
public FilePreviewer(String directory) {
tree = new JTree(new FileSelectorModel(directory));
preview = new JTextArea();
preview.setWrapStyleWord(true);
preview.setLineWrap(true);
preview.setEditable(false);
status = new JLabel(directory);
tree.addTreeSelectionListener(new TreeSelectionListener() {
public void valueChanged(TreeSelectionEvent e) {
FileNode selectedNode = (FileNode) tree.getLastSelectedPathComponent();
status.setText(selectedNode.getAbsolutePath());
if (selectedNode.isFile()) {
preview.setText(null);
try {
BufferedReader br = new BufferedReader(new FileReader(selectedNode.getAbsolutePath()));
String line = "";
while ((line = br.readLine()) != null) {
preview.append(line);
preview.append(System.getProperty("line.separator"));
}
} catch (Exception exc) {
exc.printStackTrace();
}
}
}
});
getContentPane().add(BorderLayout.WEST, new JScrollPane(tree));
getContentPane().add(BorderLayout.SOUTH, status);
getContentPane().add(new JScrollPane(preview));
setSize(800, 600);
setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
setTitle("Quick’n’Dirty File Preview");
setVisible(true);
}
public static void main(String[] args) {
new FilePreviewer("C:\\\");
}
}
The GUI includes a JTree on the left hand side, a text area in the central area, and a label holding the path to the current file at the bottom. If you provide enough memory to the JVM when running this app, you should be able to open files with this “Quick’n‘Dirty previewer”. The key part here is the definition of the anonymous inner class implementing TreeSelectionListener: it retrieves the node selected in the tree _ FileNode selectedNode = (FileNode) tree.getLastSelectedPathComponent();_ and casts it as a FileNode. This works because the getObject method of our FileSelectorModel returns an instance of FileNode. Once the current FileNode is found, it is then easy to find whether this is a file (as it is a subclass of File), and if it is, read its content to display it in the text area. The listener also updates the label with the full path of the node currently selected.
Once again, Apache commons can simplify things greatly, and if the files are not too big, you can write the TreeSelectionListener as follows:
tree.addTreeSelectionListener(new TreeSelectionListener() {
public void valueChanged(TreeSelectionEvent e) {
FileNode selectedNode = (FileNode) tree.getLastSelectedPathComponent();
status.setText(selectedNode.getAbsolutePath());
if (selectedNode.isFile()) {
try {
preview.setText(IOUtils.toString(new FileReader(selectedNode.getAbsolutePath())));
} catch (IOException exc) {
exc.printStackTrace();
}
}
}
});
That’s only for files of reasonable size, though, as the whole content of the file is stuffed into a String and then displayed in the text area.