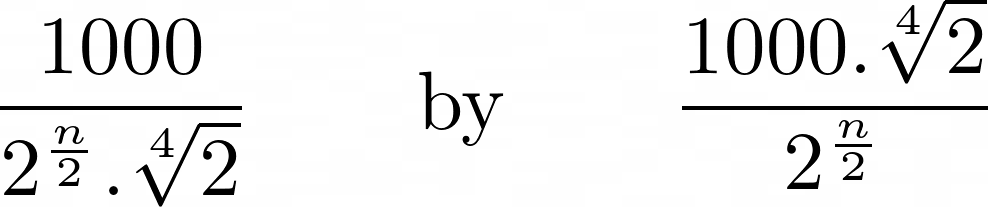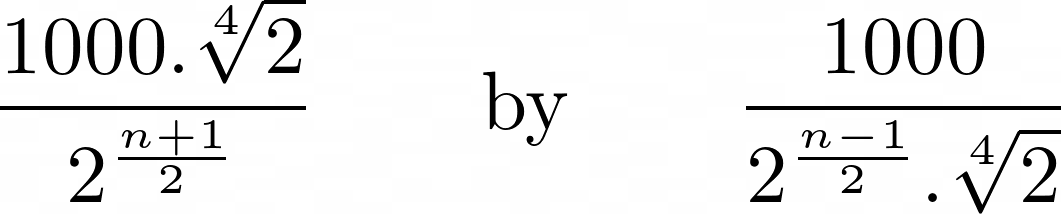In those troubled times of pandemic, it is good to be focusing on existential questions. And here is one that has been causing me to lose the little bit of hair I have left: why isn’t the A1 paper size 595 mm by 841 mm, or A5 149 mm by 210 mm?
The ISO standard defines the A series as follows:
| Size |
Format |
| 0 |
841 × 1189 |
| 1 |
594 × 841 |
| 2 |
420 × 594 |
| 3 |
297 × 420 |
| 4 |
210 × 297 |
| 5 |
148 × 210 |
| 6 |
105 × 148 |
| 7 |
74 × 105 |
| 8 |
52 × 74 |
| 9 |
37 × 52 |
| 10 |
26 × 37 |
You’ll notice that the height of a given size is the width of the previous size; a paper size is defined by “halving the preceding paper size across the larger dimension.” The base size is A0, whose area is 1m² and ratio 1:√2.
The formula given by Wikipedia gives for size i is:
\[
\alpha_A \times (2^{-\frac{i+1}{2}}) \qquad \mathrm{by} \qquad \alpha_A \times (2^{-\frac{i}{2}})
\]
In Clojure this becomes:
(defn iso-aseries-size [size]
{:size (str "A" size)
:width (* alpha-a (Math/pow 2 (- (/ (inc size) 2))) 1000.0)
:height (* alpha-a (Math/pow 2 (- (/ size 2))) 1000.0)})
with the following:
(defn fourth-root [n]
(Math/sqrt (Math/sqrt n)))
(def alpha-a (fourth-root 2))
Trying our formula, we get for the following paper sizes from A0 to A10:
pdfdata.paper> (map #(iso-aseries-size %) (range 11))
;; => ({:size "A0", :width 840.8964152537146, :height 1189.2071150027211}
{:size "A1", :width 594.6035575013606, :height 840.8964152537146}
{:size "A2", :width 420.4482076268573, :height 594.6035575013606}
{:size "A3", :width 297.3017787506803, :height 420.4482076268573}
{:size "A4", :width 210.22410381342866, :height 297.3017787506803}
{:size "A5", :width 148.65088937534014, :height 210.22410381342866}
{:size "A6", :width 105.11205190671433, :height 148.65088937534014}
{:size "A7", :width 74.32544468767007, :height 105.11205190671433}
{:size "A8", :width 52.556025953357164, :height 74.32544468767007}
{:size "A9", :width 37.162722343835036, :height 52.556025953357164}
{:size "A10", :width 26.278012976678582, :height 37.162722343835036})
If we round correctly, we get A5 595 mm × 841 mm, and other sizes also look wrong:
pdfdata.paper> (map #(iso-aseries-size %) (range 11))
;; => ({:size "A0", :width 841, :height 1189}
{:size "A1", :width 595, :height 841}
{:size "A2", :width 420, :height 595}
{:size "A3", :width 297, :height 420}
{:size "A4", :width 210, :height 297}
{:size "A5", :width 149, :height 210}
{:size "A6", :width 105, :height 149}
{:size "A7", :width 74, :height 105}
{:size "A8", :width 53, :height 74}
{:size "A9", :width 37, :height 53}
{:size "A10", :width 26, :height 37})
OK. So digging a bit more, another site gives this other formula
For size n,
- if n is even, the dimensions are:
- if n is odd, the dimensions are:
It’s not difficult to see this formula is actually identical to the previous one (\(2^\{frac{1}{4} = \sqrt^{4}{2}\)), but for the fun of writing in Clojure, here it is:
(defn iso-aseries-size [size]
(if (even? size)
{:size (str "A" size)
:width (/ 1000.0 (* (Math/pow 2.0 (/ size 2)) (fourth-root 2)))
:height (/ (* 1000.0 (fourth-root 2)) (Math/pow 2 (/ size 2)))}
{:size (str "A" size)
:width (/ (* 1000.0 (fourth-root 2)) (Math/pow 2 (/ (inc size) 2)))
:height (/ 1000.0 (* (Math/pow 2.0 (/ (dec size) 2)) (fourth-root 2)))}))
So how do we correctly calculate the dimensions? We just go back to the basic principles: set the width of the previous size as the height of the new size, calculate the area of a given size by halving the area of the previous size, round down, and divive by height to get the new width:
(defn iso-aseries-size [size]
(if (= size 0)
{:size (str "A" size)
:height (round (* 1000.0 alpha-a))
:width (round (* 1000.0 (/ 1.0 alpha-a)))}
(let [prev (iso-aseries-size (dec size))
area (* (:width prev) (:height prev))
new-area (floor (/ area 2.0))]
{:size (str "A" size)
:height (:width prev)
:width (floor (/ new-area (:width prev)))})))
which returns the correct dimensions:
pdfdata.paper> (map #(iso-aseries-size %) (range 11))
;; => ({:size "A0", :height 1189, :width 841}
{:size "A1", :height 841, :width 594}
{:size "A2", :height 594, :width 420}
{:size "A3", :height 420, :width 297}
{:size "A4", :height 297, :width 210}
{:size "A5", :height 210, :width 148}
{:size "A6", :height 148, :width 105}
{:size "A7", :height 105, :width 74}
{:size "A8", :height 74, :width 52}
{:size "A9", :height 52, :width 37}
{:size "A10", :height 37, :width 26})